Web archiving
The Libraries engage in various web archiving activities to target, capture, and preserve important web-based content.
About web archiving
Websites are informational resources documenting various events, subjects, and changes in society. These resources are often updated over time and important information can be lost. Consequently, in many cases it is imperative that this information is preserved beyond its fleeting online lifespan.
The Libraries use Archive-It to capture and crawl web content, including the University of Manitoba website and other online documentary heritage.
The material captured through Archive-It is collected for research and private study. All requests to reproduce and use the archived content must be sent to the website owner directly.
Contribute to web archive collections
Requests to capture websites or webpages and add them to our web archive collections can be submitted to the Libraries using our web archiving request form. Once a request is received, the information will be reviewed. A member of the Research Services and Digital Strategies team will follow-up on the status of your request and next steps as applicable.
Collaborative web archiving projects
UM faculties, departments, and students can work with the Libraries on web archiving projects by proposing, sponsoring and contributing to a collaborative web archiving project.
Web archive collections
-
UM Website
The University of Manitoba website, as well as websites affiliated with UM.
-
UM Faculty Websites
Websites created by UM faculty members as part of their research and professional initiatives at UM.
-
UM Student Organizations
Websites of student clubs, unions, associations, and other organizations at UM.
-
Truth and Reconciliation
Websites related to Manitoba's ongoing involvement with the Truth and Reconciliation Commission.
-
Manitoba's COVID-19 Experience
Websites documenting the COVID-19 pandemic in Manitoba from 2020-2023.
-
Archives & Special Collections
Websites donated to the Libraries' Archives & Special Collections.
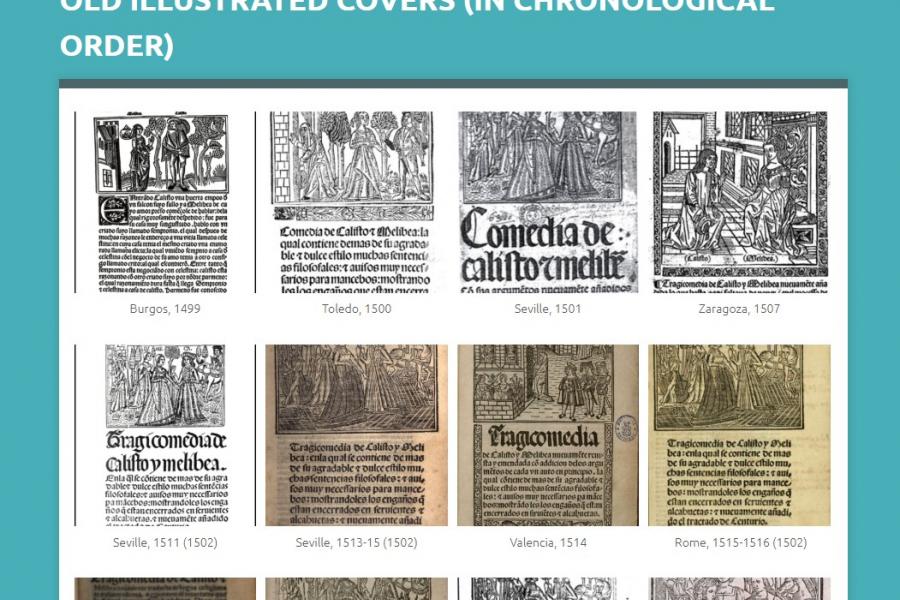
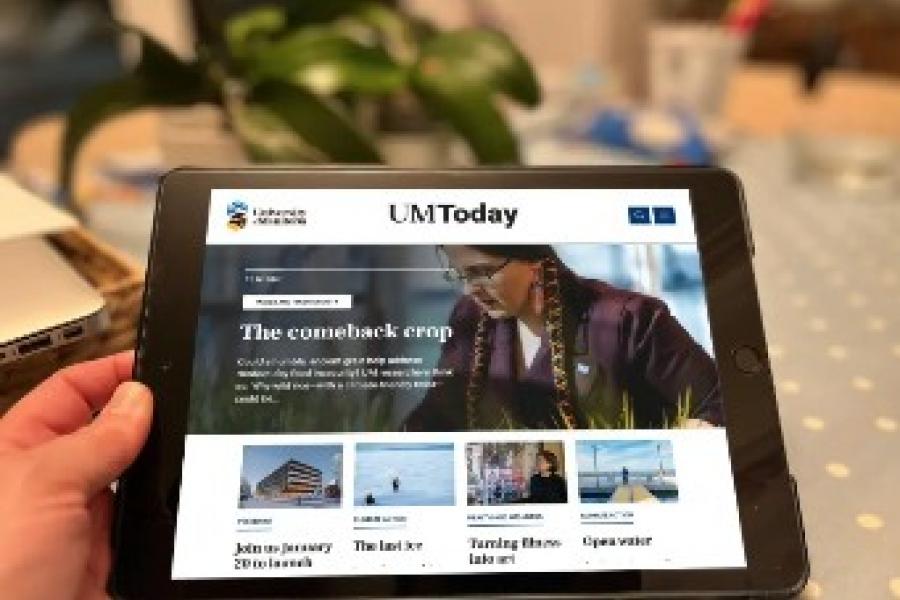
New additions to our web archive collections


Common questions about web archiving
Is personal information captured in web archiving?
The Libraries only capture and preserve copies of websites that are already publicly accessible.
Do you archive websites that are password-protected?
No, we do not capture password-protected content, unless it is under the ownership of the University of Manitoba and needs to be captured for records management purposes. The latter type of content remains private and is not made publicly accessible.
What about sites that block web crawlers?
The Libraries respect robot exclusion protocols which restrict the crawling of certain online content. Content that includes the exclusion will only be crawled with permission from the content creator.
What about copyright and ownership?
Copyright and ownership of the archived web content remain with the owner(s) identified on a website and are governed by local, national, and/or international laws and regulations. The Libraries respect the intellectual property rights and the proprietary rights of others. The Libraries assume no liability for the accuracy or lawfulness of the archived websites or the contents within them.
Can I use this content in my research?
All requests to reproduce and use the archived content must be directed to the website owner directly. The Libraries cannot authorize use of the material, nor will they act as an intermediary to the transaction. It is the responsibility of individual users of web archive collections to abide by all relevant copyright legislation and restrictions when accessing archived webpages, and to identify and contact the appropriate authority for permission.
When reproducing and using content from the Archive-It service, the Libraries encourage users to review the original website’s terms of use, as well as to inform themselves of the relevant laws applicable to their country. Users have an obligation to deal fairly with the content and may contact the Copyright Office if they are unsure of their obligations.
What type of information is captured?
In most cases, a web crawler will capture everything from HTML code, CSS files, PDFs, images, and video files. More dynamic content, such as web pages that adjust dynamically based on the browser window size, interactive maps, flash, password protected content, or functions requiring a user’s input (for example, fillable forms, “play” buttons, search boxes, login/password fields, etc.) may not be captured, or captured to a more limited extent.
Can I opt-out, or request specific content be taken down?
When a website owner authorizes communication of their work to the public without technological restrictions (such as a robot.txt exclusion), the Libraries view this as the website owner’s implicit consent to the indexing and caching of their website content. Where a site uses technological protection measures to restrict crawling technology, the UML will not harvest the content without providing notification and/or securing permission.
If someone has a legitimate complaint about the content in the University’s Archive-It account, consult the Libraries’ take-down submission process for next steps.